Hive 写入数据到Hive表(命令行)
搭建好Hadoop和Hive的运行环境之后,首先考虑到的,就是如何将数据写入到HIVE中。这篇文章将简单、快速地介绍如何通过命令行的方式,使用insert...values、load、insert...select 语句将数据写入到hive表重。并讲解了在写入数据时遇到的问题:多个小文件,以及相应的解决方案。
建库和建表
使用Hive的一个重要原因,就是hive提供了一种类似SQL的语法,称作HQL,可以以我们所熟悉的方式来管理、操作和查询数据。因为在做测试的时候会频繁地建表、删表,所以这里先介绍几个建库和建表的语句。更为详细的语句和参数说明,可以参看下面的官方文档:
- 官方Get Started文档
- 官方DDL(Data Definition Languate,数据模式定义语言)文档
- 官方DML(Data Manipulation Language,数据操纵语言)文档
创建/查看/使用/删除 数据库
本文所有的命令,均为hive命令行输入的命令。即登录linux系统后,先执行hive,进入hive命令行界面。
假设要创建的数据库名称为:tglog_aw_2018。下面的语句可以进行数据库的创建:
hive> create database tglog_aw_2018; OK Time taken: 0.018 seconds
使用下面的命令,可以查看现有的数据库:
hive> show databases; OK default tglog_aw_2018 Time taken: 0.022 seconds, Fetched: 2 row(s)
可以看到,除了刚刚创建的tglog_aw_2018库以外,还有一个名为default的默认库。
和MSSQL这样的关系数据库类似,可以使用下面的命令来切换当前操作的上下文。如果不做切换的话,那么当下面建表时会建到default库下,而我们期望是将表建在 tglog_aw_2018 下。
hive> use tglog_aw_2018;
如果想要删除数据库,可以使用drop命令:
hive> drop database tglog_aw_2018;
如果数据库不为空(其中有表存在),那么当执行drop时会报异常。
建表/查看/删除 数据表
建表可以说是Hive的核心优化点之一(分区、分桶等),建表的选项和配置也最为复杂,具体可以参看上面提供的官方文档链接。这里仅就当前的目标:写入数据,创建一个简单的表。
假设表名叫做golds_log,用来存储玩家游戏币的变化,共有5个字段:user_id(玩家id)、accounts(玩家账号)、change_type(游戏币变更类型)、golds(游戏币变更数目)、log_time(变更时间)。那么可以像下面这样创建表:
hive> Create Table golds_log(user_id bigint, accounts string, change_type string, golds bigint, log_time int);
这个表是实际项目中表的一个简化。
和查看数据库类似,可以使用show tables来查看当前数据库中的表:
hive> show tables; OK golds_log Time taken: 0.025 seconds, Fetched: 1 row(s)
可以使用drop命令来删除表:
hive> drop table golds_log;
使用Insert...Values语句写入数据
如果你和我一样,之前主要使用的是关系数据库,那么写入数据最先想到的就是Insert语句了,在Hive中也可以使用Insert语句来写入数据。假设需要向golds_log表中写入5条数据,可以执行下面的语句:
hive> Insert into table golds_log values (3645356,'wds7654321(4171752)','新人注册奖励',1700,1526027152), (2016869,'dqyx123456789(2376699)','参加一场比赛',1140,1526027152), (3630468,'dke3776611(4156064)','大转盘奖励',1200,1526027152), (995267,'a254413189(1229417)','妞妞拼十翻牌',200,1526027152), (795276,'li8762866(971402)','妞妞拼十翻牌',1200,1526027152);
正常可以看到下面的结果输出,说明在执行insert...values语句时,底层是在执行MapReduce作业。
Query ID = root_20180721130907_99fb992f-a291-41eb-af2f-a132bbf376b1 Total jobs = 3 Launching Job 1 out of 3 Number of reduce tasks is set to 0 since there's no reduce operator Starting Job = job_1531735405564_0029, Tracking URL = http://dev56:8088/proxy/application_1531735405564_0029/ Kill Command = /opt/hadoop/hadoop-2.9.1/bin/hadoop job -kill job_1531735405564_0029 Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0 2018-07-21 13:09:14,740 Stage-1 map = 0%, reduce = 0% 2018-07-21 13:09:22,124 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.35 sec MapReduce Total cumulative CPU time: 2 seconds 350 msec Ended Job = job_1531735405564_0029 Stage-4 is selected by condition resolver. Stage-3 is filtered out by condition resolver. Stage-5 is filtered out by condition resolver. Moving data to directory hdfs://localhost:9000/user/hive/warehouse/tglog_aw_2018.db/golds_log/.hive-staging_hive_2018-07-21_13-09-07_274_2944278654683659698-1/-ext-10000 Loading data to table tglog_aw_2018.golds_log MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Cumulative CPU: 2.35 sec HDFS Read: 5269 HDFS Write: 390 SUCCESS Total MapReduce CPU Time Spent: 2 seconds 350 msec OK Time taken: 17.253 seconds
此时,在windows上使用HDFS的WebUI,通过 Utilities-->Browse the file system 进入到 /user/hive/warehouse/tglog_aw_2018.db/golds_log 目录下,可以看到数据库文件:000000_0。
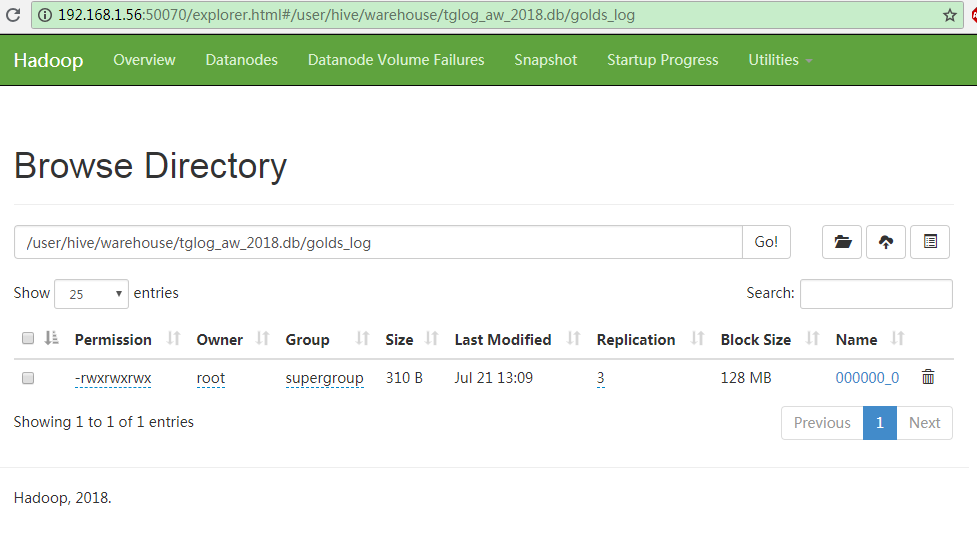
点击文件名,会出现这样的对话框,将它下载下来,可以看到它就是一个普通的文本文件,通过文本编辑器就可以查看其内容。
反复执行两次上面的insert语句,然后使用select语句,可以轻松查看到写入的内容(共15行):
hive> select * from golds_log; OK 3645356 wds7654321(4171752) 新人注册奖励 1700 1526027152 2016869 dqyx123456789(2376699) 参加一场比赛 1140 1526027152 3630468 dke3776611(4156064) 大转盘奖励 1200 1526027152 ... ... Time taken: 0.134 seconds, Fetched: 15 row(s)
再次进入webUI,刷新浏览器,会看到目录变成了如下这样:
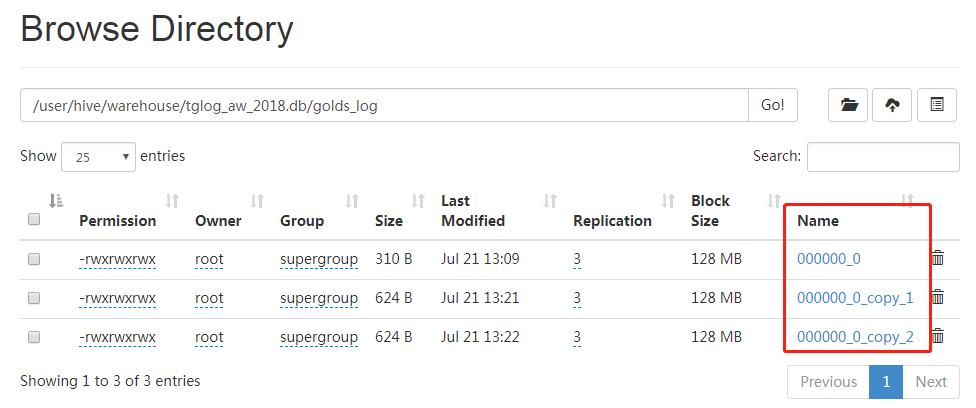
说明:每次执行Insert语句(底层执行MapReduce任务)都会生成独立的数据文件。对于HDFS来说,优势是存储少量大文件,不是存储大量小文件。而对于我们的应用而言,每10分钟就会同步一次数据到Hive仓库,如此一来会生成无数的小文件,系统的运行速度会越来越慢。所以第一个问题就是:如何合并小文件?
合并数据库小文件
在建表的时候,我们没有指定表存储的文件类型(file format),默认的文件类型是Textfile,所以,当我们下载生成的000000_0文件后,使用编辑器可以直接查看其内容。
Hive提供了一个 ALTER TABLE table_name CONCATENATE 语句,用于合并小文件。但是只支持RCFILE和ORC文件类型。
除了Textfile,还有RCFILE、ORC、PARQUET、AVRO、JSONFILE、SEQUENCEFILE 等文件类型。具体差别先请自行谷歌。
因此,如果想合并小文件,可以删除表,然后再使用下面的命令重建:
hive> Create Table golds_log(user_id bigint, accounts string, change_type string, golds bigint, log_time int) STORED AS RCFile;
重复上面的过程,执行3次insert语句,每次插入5条数据。刷新WebUI,会看到和前面一样产生3个文件。
如果你此时再将000000_0下载下来,用文本编辑器打开查看,发现已经是乱码了。因为它已经不再是文本文件了。
接下来,执行下面的语句,对文件进行合并:
alter table golds_log concatenate;
刷新WebUI,会发现文件已经合并了,这里就不再演示了。
使用Load语句写入数据
除了使用insert语句以外,还可以通过load语句来将文件系统的数据写入到数据库表中。删除刚才创建的表,然后使用下面的语句重新创建:
hive> Create Table golds_log(user_id bigint, accounts string, change_type string, golds bigint, log_time int) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
上面最重要的一句就是ROW FORMAT DELIMITED FIELDS TERMINATED BY '|',说明表的字段由符号“|”进行分隔。
然后准备要导入的文件:golds_log.txt。
3645356|wds7654321(4171752)|新人注册奖励|1700|1526027152 2016869|dqyx123456789(2376699)|参加一场比赛|1140|1526027152 3630468|dke3776611(4156064)|大转盘奖励|1200|1526027152 3642022|黑娃123456(4168266)|新人注册奖励|500|1526027152 2016869|dqyx123456789(2376699)|大转盘奖励|1500|1526027152
将这个文件上传至linux的文件系统下,比如说 /root/tmp/golds_log.txt。然后执行下面的命令进行导入:
hive> Load data local inpath '/root/tmp/golds_log.txt' into table golds_log; Loading data to table tglog_aw_2018.golds_log OK Time taken: 0.657 seconds
因为golds_log.txt中包含有中文,确保文件格式是utf-8(GB2312导入后会有乱码)。
你会发现使用load语句写入数据比insert语句要快许多倍,因为HIVE并不对scheme进行校验,仅仅是将数据文件挪到HDFS系统上,也没有执行MapReduce作业。所以从导入数据的角度而言,使用load要优于使用insert...values。
我尝试过使用其他更不常见的分隔符来代替“|”,比如 特殊符号组合: <|>,特殊符号:↕,非常用汉字:夨。都有各自的问题,比如说用↕,导入后的结果变成了类似这样:
NULL wds7654321(4171752)� 妞妞拼十翻牌� NULL 1526027152
NULL dqyx123456789(2376699)� 妞妞拼十翻牌� NULL 1526027152
NULL dke3776611(4156064)� 妞妞拼十翻牌� NULL 1526027152
NULL 黑娃123456(4168266)� 妞妞拼十翻牌� NULL 1526027152
NULL dqyx123456789(2376699)� 妞妞拼十翻牌� NULL 1526027152
应该是只可以用一个字节的的ASCII字符,↕是UTF8字符,占2或3个字节,HIVE在实际处理的时候,只取了后面的一个字节,然后把前面的字节归为正常的字段,所以可以看到虽然正确的划分了字段,但是数字为NULL了(因为数字多了一个字节就不是数字了);最后一个数字仍显示正确,因为后面的一个字节作为分隔符了。
反复导入3次后,打开Web UI,刷新后,发现和使用Insert语句时一样,每次load语句都会生成一个数据文件,同样存在小文件的问题。
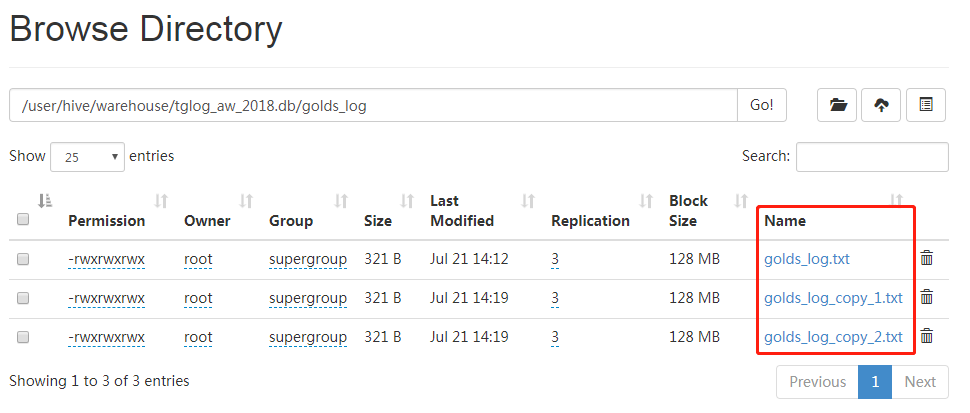
和前面的方法一样,我们可以将表的存储类型改为RCFile,然后再进行合并,但是因为使用load语句的时候,要导入的文件类型是txt,和表的存储类型不一致,所以会报错。这时候,只能曲线救国了:将主表创建为RCFile类型,再创建一张临时表,类型是Textfile,然后load时导入到临时表,然后再使用下一节要介绍的Insert...select语句,将数据从临时表导入到主表。
使用Insert...Select语句写入数据
使用下面的语句创建一张临时表,临时表的名称为golds_log_tmp。临时表在当前会话(session)结束后会被HIVE自动删除,临时表可以保存在SSD、内存或者是文件系统上。
hive> Create TEMPORARY Table golds_log_tmp(user_id bigint, accounts string, change_type string, golds bigint, log_time int) ROW FORMAT DELIMITED FIELDS TERMINATED BY '|';
使用下面的语句创建主表:
hive> Create Table golds_log(user_id bigint, accounts string, change_type string, golds bigint, log_time int) STORED AS RCFile;
使用下面的语句将数据导入到临时表:
hive> Load data local inpath '/root/tmp/golds_log.txt' into table golds_log_tmp;
使用insert...select语句将数据从临时表转移到主表:
hive> Insert into table golds_log select * from golds_log_tmp; ... MapReduce Jobs Launched: Stage-Stage-1: Map: 1 Cumulative CPU: 1.58 sec HDFS Read: 6177 HDFS Write: 947 SUCCESS Total MapReduce CPU Time Spent: 1 seconds 580 msec OK Time taken: 16.886 seconds
insert...select语句底层也会执行一个MapReduce作业,速度会比较慢。
在多次执行insert...select后,golds_log下仍然会生成多个小文件,此时,只要执行一下合并小文件的语句就可以了:
hive> alter table golds_log concatenate;
至此,关于使用命令行对Hive进行数据导入的介绍就先到这里了。接下来,应该是使用ODBC/JDBC连接到Hive,通过编程的方式来对Hive进行操作了。
感谢阅读,希望这篇文章能给你带来帮助!