Kafka + Spark Stream实时WordCount
2018-10-28
张子阳
分类: 大数据处理
Word Count简直就是大数据届的hello world。所谓Word Count就是计算一行或者一段文本中英文单词的出现个数(英文单词以空格分隔)。这篇文章示范了如何使用Kafka + Spark Streaming来实现一个实时版本的Word Count。这个范例比较简单,仅仅有助于跑通流程。在实时运算时,一个很重要的问题就是:时间窗。比如说,统计实时的在线人数,当有新用户上线时,在线人数+1,但是过15分钟后,如果该用户的“最后活跃时间”仍是上线时间,那么此时就要去除它。
Word Count这个例子没有时间窗的概念,所以有点过于简单,但对于初次接触的同学,理解实时计算是什么样的还是有一点帮助吧。
# coding=utf-8
# 提交Spark作业
# $SPARK_HOME/bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.3.1 /data/pyjobs/test/kafka-wordcount.py
from __future__ import print_function
from pyspark.sql import SparkSession
from pyspark.sql.functions import explode
from pyspark.sql.functions import split
from pyspark.sql import functions as F
bootstrapServers = "kafka1:9092,kafka2:9092,kafka3:9092"
spark = SparkSession\
.builder\
.appName("StructuredKafkaWordCount")\
.getOrCreate()
# 基于来自kafka的数据流,创建dataframe
lines = spark\
.readStream\
.format("kafka")\
.option("kafka.bootstrap.servers", bootstrapServers)\
.option("subscribe", "test.wordcount.input")\
.option("failOnDataLoss", False)\
.option("group.id", "wordcount-group3")\
.load()\
.selectExpr("CAST(value AS STRING)")
# 将单行数据拆分,转成多行数据
words = lines.select(
explode(split(lines.value, ' ')).alias('word')
)
# 对单词进行分组,并计算总数
wordCounts = words.groupBy('word').count()
# 将两列数据合并成单列数据
wordCounts = wordCounts.select(F.concat(F.col("word"), F.lit("|"), F.col("count").cast("string")).alias("value"))
# 测试时,可以不将结果写入kafka,直接输出到控制台
# query = wordCounts \
# .writeStream \
# .outputMode("complete") \
# .format("console") \
# .start()
# 将结果输出到 test.wordcount.output
query = wordCounts \
.writeStream \
.format('kafka') \
.outputMode('update') \
.option("kafka.bootstrap.servers", bootstrapServers) \
.option('checkpointLocation', '/spark/job-checkpoint') \
.option("topic", "test.wordcount.output") \
.start()
query.awaitTermination()
提交Spark作业之前,需要先创建两个Kafka的topic:test.wordcount.input,用于录入数据,由Spark读取,进行运算后,再写入到 test.wordcount.output 中:
# 创建和写入 test.wordcount.input # bin/kafka-topics.sh --zookeeper zookeeper1:2181/kafka --create --topic test.wordcount.input --replication-factor 2 --partitions 6 # bin/kafka-console-producer.sh --broker-list kafka1:9092 --topic test.wordcount.input # 创建和读取 test.wordcount.output # bin/kafka-topics.sh --zookeeper zookeeper1:2181/kafka --create --topic test.wordcount.output --replication-factor 2 --partitions 6 # bin/kafka-console-consumer.sh --bootstrap-server kafka1:9092 --topic test.wordcount.output
关于kafka的控制台命令,可以参看:Kafka分布式消息系统(通过控制台访问) - Part.4
有一点需要注意的:在执行spark-submit的时候,需要加上--packages org.apache.spark:spark-sql-kafka-0-10_2.11:2.3.1 选项,因为要读取/写入Kafka topic。
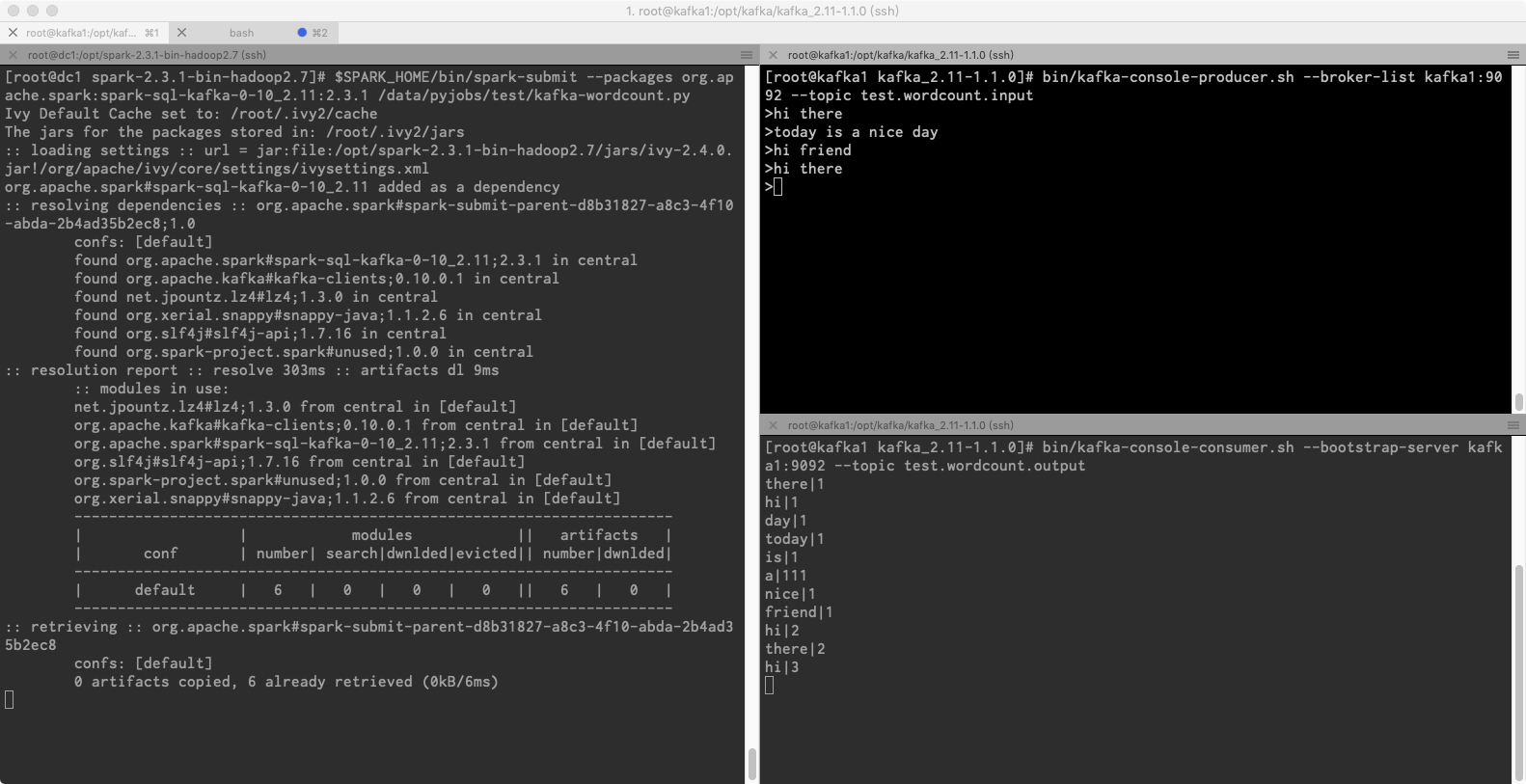
上图左边,是Spark作业的提交窗口;右上方是字符的录入窗口,右下方是结果窗口;每当在右上方输入句子时,便会在右下方实时计算出单词的出现数量。
此时如果想进一步处理(例如进行显示),只需要编写一个kafka的客户端,从test.wordcount.output中读取数据就可以了。
至此,就完成了实时Word Count这个范例。以后会再做一个加入“时间窗”的更贴近实际项目的范例吧。
感谢阅读,希望这篇文章能给你带来帮助!